【考完】不确定的考题与答案#
- 模糊集的并是否和经典集合的并兼容?—— 是的
- 二次型优化中,Steepest Descent 每次的步长固定吗?—— 是的
- 统计图像处理中,ICM算法算贪心的吗?—— 是的 (nooo猜错了)
形态学#
形态学运算定义#
二值形态学与灰度形态学 扩张(Dialtions)、侵蚀(Erosions)、开运算(Opening)、闭运算(Closing) 的定义
二值形态学#
Structing Elements (SE) 结构元,也就是卷积核非0部分的形状。后面记为 B∈Z2,是二维坐标(向量)的集合。
二值·侵蚀(Erosions): A⊖B={p∣(B)p⊆A}
表现为白色缩了一圈、黑色扩了一圈。
其中 (B)p={b+p∣b∈B},整个式子的意思是:B 平移后在 A 中的点构成的图,叫做 B 侵蚀 A 的结果。
二值·扩张(Dialtions): A⊕B={p∣(B^)p∩A=∅}
表现为黑色缩了一圈、白色扩了一圈。
其中 B^={(−x,−y)∣(x,y)∈B},也就是移回去在 A 内的点的集合。
更简单的写法:A⊕B=⋃p∈A(B)p
对原图的操作 ⇔ 对补图的另一个操作的补(对偶):
(A⊖B)c(A⊕B)c=Ac⊕B^=Ac⊖B^
用上面的定义可以很简单地证明。
开运算(Opening): A∘B=(A⊖B)⊕B —— 先小后大
闭运算(Closing): A∙B=(A⊕B)⊖B —— 先大后小
性质:
- 幂等——做1w次=做1次
- 不改变包含关系
- 大小关系: A∙B⊆A⊆A∘B
- 对偶
灰度形态学#
灰度时取补就是相反数(二值时取非)。
如果不是为了考试,其实记灰度的就够了。这个更统一更好背。推广到二值就是把 max 变成了 OR,把 min 变成了 AND。
flat SE: SE是二值的MASK,“平的”
- 侵蚀: [f⊖b](x,y)=min(s,t)∈b{f(x+s,y+t)}
- 扩张: [f⊕b](x,y)=max(s,t)∈b{f(x−s,y−t)}
nonflat SE: 有相对大小变化的SE
- 侵蚀: [f⊖bN](x,y)=min(s,t)∈bN{f(x+s,y+t)−bN(s,t)}
- 扩张: [f⊕bN](x,y)=max(s,t)∈bN{f(x−s,y−t)+bN(s,t)}
开闭运算定义不变,不过此时集合倒是不存在了——所以只有幂等和对偶性。
形态学的应用#
二值形态学重建#
目标:二值图 G 有多个不连通的部分,给你一个部分的种子,要把包含这个种子的部分提取出来。
本质上就是从这个种子开始 广度优先 遍历图内像素,不过这里用 扩张运算 实现了广度优先。评价为计算开销更大,垃完了。
记种子图为 I0,具体做法:
Ik=(Ik−1⊕B)∩G
也就是先扩张,然后把区域外的切掉,循环直到收敛。显然部分之间的最小间距不能比SE直径小(还有限制,真不如广度优先一根)。
但是把 ∩ 看作 ∧,进而变为“min”,就能得到灰度形态学重建:
灰度形态学重建 H-dome#
此时形态学的优势才体现出来。种子图 I0=G−c,显然 I0 就是原图暗了一些。
IkG′=min(Ik−1⊕B,G)=G−I∞
迭代过程中像素值和原值的差异在 c 以内,而深色部分和原值的差异比浅色部分更小,因为扩张是求max,是局部最亮拉动局部最暗,但局部最亮没有像素拉,导致其与原始的差值始终为 c。
这个“局部”是用min实现的,如果没有min,经过无数次迭代,整张图就成局部了。min制造了沟壑,防止了蔓延。
由此可见:c 是重建后的最大灰度,也是对“局部范围内,前景和背景灰度差”的估计。
Convex Hull 找凸包#
二值形态学中的。基本原理:
Ii,kIch=(Ii,k−1⊖Bi)∪Ii,k−1=i=1,2,3…⋃Ii,K
其中 Bi 的设计很有意思:如果要生成的边为45°的方形,那么一共设置4个 B,生成左边那个尖角的SE长这样:
为什么生成的的是90°?因为“1”和中心点的连线覆盖了90°。所以如果是下面的形态元:
生成结果左边的尖角会是 2arctan(0.5)。显然取最终并集的时候得到的不是凸包——会有四个向内凹陷的钝角。
为什么是“并”?很显然——侵蚀会减小面积;
为什么是 “侵蚀”?需要思考一下:仅有当结构元处都是1,才能将“与中心连线”的那个三角填上颜色。如果是 “扩张”,那就变成广度优先遍历了。
本质上是提取高频(比结构元小的东西)。之所以叫“顶帽”,指的就是得到的是小突起(整张图像是广场,最高的是帽子)。
对灰度图,作业里用这个方法求不均匀光照下的二值化:先用这个变换消除背景的不均匀,再全局阈值。
记原图为 f,形态元为 b,结果为 h,背景暗而目标亮使用:
h=f−(f∘b)
灰度的开运算结果一定比原值小,相当于提取了背景。形象化的理解是:开运算把亮的部分消除了,并用临近值填充了原来亮的位置。
如果背景暗而目标亮,就反过来:
h=(f∙b)−f
要求形态元比要保留的大。 作业里是松散的米粒,何尝不是一种 cherry pick。
边缘提取#
以提取浅色区域为例:
h=f−(f⊖b)
非常显然,相当于白色先缩小一点,让出边界的位置。
模糊方法#
模糊集合论基本定义#
元素 z 属于模糊集 A 的程度——隶属度
μA(z)∈[0,1]
定义集合需要用 (元素,隶属度) 的二元组的集合:
A={(z,μA(z))∣z∈Z}
对,全集 Z 的每一个元素都在A里,只不过是隶属度的高低罢了。
模糊集的运算:对 ∀z∈Z:
- 空: μA(z)=0
- 集合相等: μA(z)=μB(z)
- 子集: μA(z)≤μB(z)
- 补(NOT): μAˉ(z)=1−μA(z)
- 并(OR): μA∪B(z)=max(μA(z),μB(z))
- 交(AND): μA∩B(z)=min(μA(z),μB(z))
模糊推断系统基本概念#
- 模糊化(Fuzzification):将 crisp 输入转换为模糊语言变量(使用隶属函数)
- 知识库(Knowledge Base):包含隶属函数和模糊规则
- 推理机制(Inference):应用 if-then 规则将模糊输入映射为模糊输出
- 去模糊化(Defuzzification):将模糊输出转换为 crisp 输出
专家知识就是规则,表现为一系列“if-then”:
- 规则内部的条件使用 AND 连接多个前提。then 的处理分为两大方法,见下
- 规则之间使用 OR 连接
例子:图像增强
Expert knowledge (linguistic rule)
- If a pixel is dark, then make it darker
- If a pixel is gray, then keep it gray
- If a pixel is bright, then make it brighter
记输入为 i1,输出为 i2,有:
Expert knowledge (reiterated)
- i1 is “dark” and i2 is “darker”
- i1 is “gray” and i2 is “gray”
- i1 is “bright” and i2 is “brighter”
这里为什么 “蕴含” 也用了AND?这是 Mamdani 模型,类似联合概率;而 “以条件隶属度为权值对then进行加权” 是 Takagi-Sugeno 模型。
课上只讲了 Mamdani 模型。举个例子:
- 如果输入满足条件1 => 输出满足要求1
- 如果输入满足条件2 => 输出满足要求2
- 否则 输出满足要求3
- 规则1隶属度(输出)=min( 条件1(输入), 要求1(输出) )
- 规则2隶属度(输出) = min( 条件2(输入), 要求2(输出) )
- 规则3隶属度(输出) = min( 要求3(输出) )
每个隶属度的具体计算需要定义,也就是“知识库”
这里没有考虑 if-else 的关系:规则之间平行
总隶属度(输出)=max(规则1隶属度(输出),规则2隶属度(输出),规则3隶属度(输出))
“总隶属度”是变量“输出”的函数,下一步就是遍历所有可能的输出值,计算每个输出值的总隶属度,最后用某种去模糊方法(见下)得到最终结果。
去模糊化方法#
- 重心法(centroid of gravity): 对上面的例子来说,就是用每个“输出”的隶属度作为权重,对“输出”计算加权平均。
- Bisector of area:找到一个输出值,使得这个输出值的总隶属度曲线下面积被分成两半。
- Mean of maximum:找到总隶属度曲线的最大值,求出所有输出值对应的总隶属度等于这个最大值的输出值的平均。
- Smallest of maximum:找到总隶属度曲线的最大值,求出所有输出值对应的总隶属度等于这个最大值的输出值中的最小。
- Largest of maximum:找到总隶属度曲线的最大值,求出所有输出值对应的总隶属度等于这个最大值的输出值中的最大。
大津法、模糊分割方法优化的目标函数#
大津法OTSU#
理想情况是图像有两个峰,最佳阈值在两个峰之间的谷底。大津法的目标是找到一个分界点,左侧的方差和右侧的方差的加权平均最小(刚好分离两个峰),这就是最小化类内方差。根据“总方差=类间方差+类内方差”,可知等效于最大化类间方差。
总方差:σ2=N1∑i=1N(xi−μ)2
||
类内方差:Nn0σ02+Nn1σ12
+
类间方差:Nn0(μ0−μ)2+Nn1(μ1−μ)2=Nn0Nn1(μ0−μ1)2
OTSU没有解析解,要遍历所有可能的阈值,计算每个阈值对应的类内方差或类间方差,找到最优的那个。
模糊分割方法#
假设阈值为 t,小于 t 的像素的均值为 μ0,大于等于 t 的像素的均值为 μ1。对于像素值 X,在给定 t 时,其属于当前划分的隶属度由下式给出:
μX(X)={1+C∣X−μ0∣1, X<t1+C∣X−μ1∣1, X≥t
其中 C=256。目标函数有多种,作业里是最小化熵:
targminm,n∑H(μX(Xm,n))
这里熵是把隶属度看作概率,用二分类的熵:
H(p)=−plogp−(1−p)log(1−p)
要最小化熵,就要让p接近0或1,考虑到给出的隶属度公式,也就是让其和 当前类别的均值 尽可能接近,也就是最小化类间方差了。实际实验中,模糊分割对不均匀亮度的适应性,比OTSU更好(作业用的是四个灰度不一的物品,在黑色背景上)。
考题:让算了一下某个(输入,输出)对所有规则的隶属度
模糊聚类方法基本概念#
- 硬聚类:每个数据点只能属于一个簇
- 模糊聚类:每个数据点可以属于多个簇
Fuzzy C-Means (FCM) 的目标函数:
minJ=i=1∑Nj=1∑Krijm∥xi−cj∥2
其中:
- N 是数据点的数量
- K 是簇的数量
- xi 是第 i 个数据点
- cj 是第 j 个簇的中心
- rij 是数据点 xi 属于簇 j 的隶属度,课件上要求求和为1。
- m∈[1,∞) 是模糊指数,控制了模糊程度。当 m→∞ 时,所有数据点对所有簇的隶属度趋于相等,会将所有数据点归为一类。
更新簇中心的公式:
cj=∑i=1Nrijm∑i=1Nrijmxi
对于 Kmeans,rij 是一个二值变量,表示数据点 xi 是否属于簇 j。对于模糊聚类,rij 是一个连续变量,表示数据点 xi 属于簇 j 的程度。
统计方法#
- 伯努利统计:就是二项分布,抛硬币,组合数
- 贝叶斯统计基本概念
简要说说作业吧。
1. 最小二乘复原#
有向量 x,经过 变换矩阵 A 变成 y,有噪声 n(高斯噪声,每个维度的方差不一样),所以 y=Ax+n。已知 A 和 y,求 x 的估计 x^。方法是最小二乘(矩阵的二范数也是逐项平方和):
x^=zargmin∥y−Az∥2
求个导,顺别复习一下矩阵求导(也可以展开逐项套公式):
d∥y−Az∥2dzd∥y−Az∥2ATAzz=dtr((y−Az)T(y−Az))=tr{(−Adz)T(y−Az)−(y−Az)TAdz}=tr{(Adz)T(Az−y)}+tr{(Az−y)TAdz}=2tr((Az−y)TAdz)都是标量,直接转置直接加=tr([2AT(Az−y)]Tdz)整理成dL=tr((∂W~∂L)TdW~)=2AT(Az−y):=0=ATy=(ATA)−1ATy
重建后均方误差为 10,可见效果并不行,这是因为每个维度一视同仁。
考题:最小二乘求导结果?(主要是有没有2)
2. 统计理论下的最小二乘#
也就是用贝叶斯方法讲述了如何加权。
x^=xargmaxP(x∣y)=P(y)P(y∣x)P(x)=xargmaxP(y∣x)(无先验概率时)=xargmaxi∏exp−2σi2(yi−aiTx)2 =xargmini∑σi21(yi−aiTx)2取了对数=xargmini∑(σiyi−σiaiTx)2
最后一步相当于求解:
(Σ⋅A)⋅x=Σ⋅y
的最小二乘解,其中
Σ=1/σ10⋮001/σ2⋮0......⋱...00⋮1/σn
实现了对每个维度的加权,方差越大(越模糊),重要性越小,防止影响到其他更确定的维度。说实话这和我想当然的结果恰好相反,蛮有趣的。重建后均方误差为 0.03,效果非常好。
3. 图像复原#
- 模糊图像 Iblur:将原图拉成一个高维向量,乘上一个很大的矩阵 A,然后加上了标准差为 σblur=0.01 的高斯噪声。
- 噪声图像 Inoisy:将原图加上标准差为 σnoisy=20 的高斯噪声
要在输入为 这两个图像、已知 A 和 σblur 和 σnoisy 的情况下,复原出原图。
最简单的做法是直接对 Iblur 用最小二乘,但是数值爆炸了。需要加入正则项才能重建(惩罚过大的结果),虽然效果很不错,但是要调参。
另一种方法是建立概率模型:
I^=IargmaxP(I∣Iblur,Inoisy)=P(Iblur∣I)P(Inoisy∣I)P(I)/P(Iblur,Inoisy)=IargmaxP(Iblur∣I)P(Inoisy∣I)(没有先验)=Iargmaxexp(−2σblur2(Iblur−AI)2)exp(−2σnoisy2(Inoisy−I)2)
可以求得理论解,均方误差比精调的正则化差一些。
基本的优化方法#
- 模拟退火:如果随机偏移后更优就接受,否则以概率 exp{−TΔE} 接受,其中 ΔE 是目标函数变差的量;T 是随着迭代逐渐降低的温度。
- 最速下降法(Steepest Descent):梯度下降中步长通过搜索决定。在已知梯度方向的情况下,沿着这个方向搜索一个最优的步长,使得目标函数在这个方向上取得最小值。
- 共轭梯度法(Conjugate Gradient):专门用于二次凸优化。
- AdaGrad:累积了所有历史平方项,开方后用于分母,显然会越学越慢。
- RMSProp:AdaGrad的基础上改成了EMA,防止了越学越慢的问题。
- Momentom法:用EMA的方式将最新的梯度作用到方向上(好像原始的不是EMA?是衰减历史后直接加上)。其实就是用低通滤波后的梯度来更新。
- Adam:EMA momentum 缝合 RMSProp
图象采集与处理——拜尔Bayer滤镜#
四个格子对应最终一个像素。四个格子中滤光片颜色顺时针分别是:红、绿、蓝、绿。最终像素的RGB值由这四个格子的值通过插值计算得到,不是四合一。
由此可以解释为什么拍摄细条纹会有颜色:遮住了某列格子,导致只有“红绿”或“蓝绿”或“红蓝”或“绿绿”。
图象分割与配准#
哈里斯角点检测#
“角点”的定义:有一个小窗口,无论在什么方向移动一段距离后,窗口内的(某种平均)像素值发生了较大的变化,则原来的窗口内有角点。要体现一个角,肯定要用窗口观察啦。
这似乎和“角”这个图形概念距离有些远。这样看:如果窗口内有一个角,则无论什么方向移,必然导致角内区域的增加或减少,也就是窗口内一定会有某些位置,其像素值发生了较大变化;而如果是边,沿着边移动就不会有任何变化;如果平坦区域,怎么移动都没有变化。
下面用数学语言描述。“变化”用平方偏差表示,窗口函数负责了“平均”:
E(u,v)=x,y∑w(x,y)[I(x+u,y+v)−I(x,y)]2
化简一下,泰勒展开,只取一阶量:
E(u,v)≈x,y∑w(x,y)[Ixu+Iyv]2=(uv)(Ix2IxIyIxIyIy2)(uv)
早期有只取几个方向的,比如Moravec角点检测算子;这里要任意方向,发现保留一阶量可以用二次型理论分析。
那个矩阵记为 M,进行如下的特征值分解:
M=(Ix2IxIyIxIyIy2)=R−1(λ100λ2)R
因为 M 是对称矩阵,所以 R 是正交矩阵,R−1=RT,有旋转的含义(实际上所有正交矩阵都可以被看作是旋转或反射)。所以这实际上消除了“角”的旋转,角度上归一了。
正交矩阵作用于任何向量,都不会改变向量长度。此时:
E(u,v)≈(uv)R−1(λ100λ2)R(uv)=(u′v′)(λ100λ2)(u′v′)=λ1u′2+λ2v′2
如果是角点,那么对于 ∀(u,v),E(u,v) 都较大,也就是特征值都较大;如果是边,那么存在一个方向使得 E(u,v) 较小,也就是一个特征值较小;如果是平坦区域,那么对于任意方向 E(u,v) 都较小,也就是两个特征值都较小。
形象化理解:仅保留一阶量的E,画出来其实是三维空间的一个抛物面,输入是平面的一个点,值为高度。M 的特征值决定了这个抛物面的形状,R 决定了方向。如果是角点,抛物面就是碗的形状;如果是边,抛物面就退化为一个沟壑(截面是抛物线);如果是平坦区域,抛物面就退化为一个平面。
所以只要计算每个像素点的 M,再计算 M 的两个特征值,施加简单的阈值,就能判断这个区域的类型了。
Harris的做法是定义一个角点响应函数:
F=det(M)−k⋅trace(M)2=λ1λ2−k(λ1+λ2)2
只要一个维度的阈值就够了(另一个阈值转移到了 k 的选择)。也无需显式计算特征值了。
Shi-Tomasi的做法是直接用 min(λ1,λ2) 作为响应函数,直接对这个值进行阈值判断。
还有一个问题:窗口取多大?实际上Harris角点没有尺度不变性。比如待检测的是一个圆角,如果窗口比圆角半径大,可以检测;如果窗口很小,那看起来就是边。
SIFT#
目标是从图像中构造特征,这些特征有旋转不变性和尺度不变性。分为两步:先确定特征点的位置和尺度,然后在这些地方确定方向、进而得到特征。
提到旋转不变性,首先便想到了“Harris角点检测算子”。但是Harris角点检测算子没有尺度不变性。所以SIFT有一个简单的想法:用不同尺度的算子,得到不同尺度的特征点。不过SIFT用的不是Harris角点检测用到的一阶微分,而是二阶的。
一阶和二阶微分#
这里一阶和二阶指的是高斯曲线的。对于一维高斯,一阶的形状是一个峰跟着一个谷,从匹配滤波的角度来看,匹配的是断崖;二阶的形状是一个盆地,中间非常凹陷,两边略微突起。所以SIFT实际匹配的是暗斑。
Harris实际实现的时候往往采用 [1, 0, -1] 这样的卷积核(两侧可以补0)。尺度变大后,一般就用高斯的一阶导数代替,根据卷积的结合律和交换律,相当于先高斯模糊、再用最小的卷积核 [1, -1]。
Laplacian of Gaussian (LoG) 的定义是 ∇2f=∂x2∂2f+∂y2∂2f,直接求和了。为什么一阶导不能直接求和?因为没有什么含义;而某个方向的二阶导的含义是向上还是向下凹,所以两个维度求和后,就有了“平均凹凸”的含义:如果是正的,说明向下凹;如果是负的,说明向上凹。
这个求和就很友好:每个位置只得到一个值(二阶梯度之和),而不是两个值(两个方向的梯度)。当然如果算一阶导的幅度,倒是也会产生一个类似二阶导形状的结果,但是……看图吧:
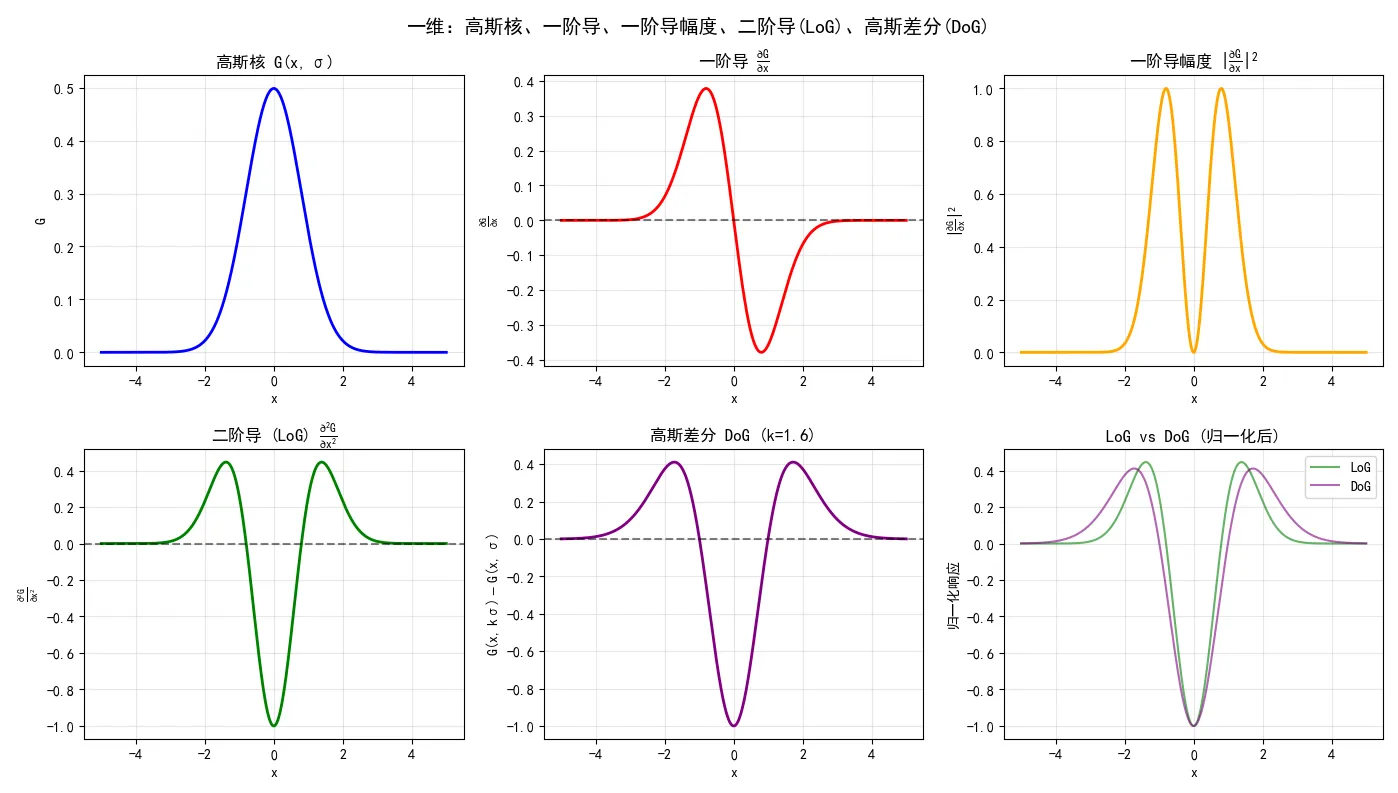
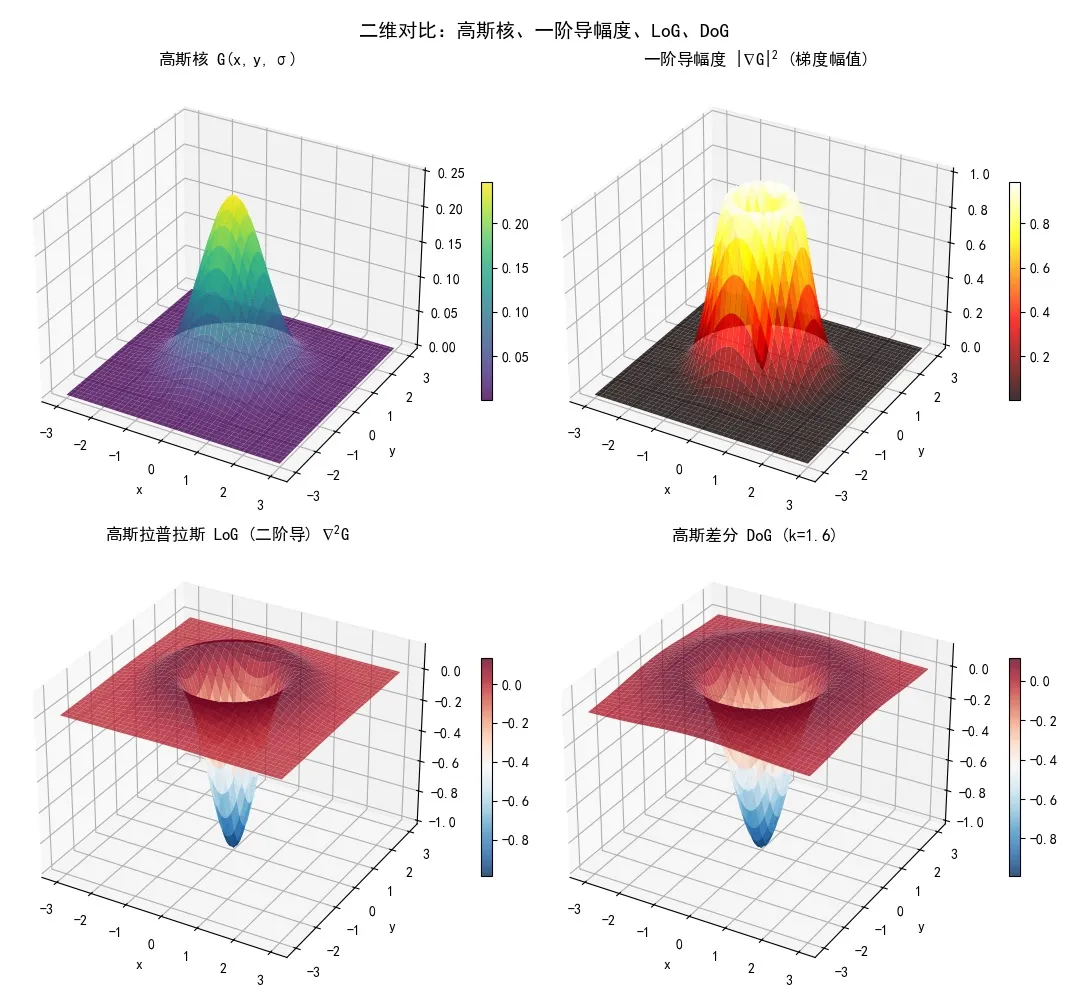
SIFT实际做法是用 DoG(Difference of Gaussian)来近似 LoG,因为两者非常接近(见上方图示),但 DoG 的计算更简单。顾名思义,DoG 就是两个不同模糊度的高斯图像相减。SIFT 在这里进一步做了优化,后面再说。
确定关键位置和尺度#
根据匹配滤波的原理,对于目标特征位置——即暗斑,应该存在一个大小的LoG(凹陷的尺寸),使得响应最大。SIFT的做法简单粗暴:对于每个位置,遍历所有尺度的LoG,用响应最大的那个尺度。出于计算效率的考虑,LoG用DoG近似,因此具体步骤为:先对图像进行不同程度的高斯模糊,得到一系列模糊图像;然后相邻的模糊图像相减,得到一系列DoG图像;最后在这些DoG图像中寻找局部极值点,这些点就是潜在的特征点。
有几个优化(按照发挥作用的阶段排序):
- 降采样。进行高斯模糊相当于低通滤波,根据采样定理,当图像最高频小于采样频率的一半时,可以进行降2采样,此时不会损失任何信息。这其实很类似 CQT 的快速算法:在一个八度(octave)内设定一组卷积核,计算完高斯模糊后,选取某一张模糊结果进行降2采样,得到新的八度;新的八度同样处理。为了保证降采样后可以用完全相同的卷积核组,应该在 卷积核尺度首次 ≥ 最小直径两倍 的那张图上进行。这样,下一组八度的卷积核相当于上一组卷积核大小翻了一倍,但计算量少了很多。
- 迭代模糊(可选)。考虑到高斯过程的可分离性,可以在上一次模糊的结果上进行模糊,这样可以让卷积核尺寸较小。
- 插值定位极值点。由于图像是离散的,找到的极值还需要经过插值、找到更精确的位置。一维的情况下可以用抛物线插值,现在是三维的情况(图像本身是二维的;又堆积了尺度)。具体做法懒得深究了。最终能得到一个更精确的小数位置和此时的极值。
- 低对比度点舍弃。如果找到的极值小于某个值就直接丢弃,视为这个特征不够明显,不能矮子里面拔将军。
- 消除边缘效应。好的特征,比如暗斑和角点,应该在所有方向上都有显著变化。但是DoG会筛选出边沿,所以需要滤除。具体做法就是 Harris角点检测 用到的特征值方法。这里还可以利用这两个特征值对局部进行放射变换,将特征拉回到圆形。
经过这么一系列操作,就能得到一系列特征点的位置和尺度了。
提取特征#
特征其实是梯度方向的直方图。首先要统一方向。具体做法是统计尺度范围内的梯度方向,用投票最高的方向作为主方向,用该方向进行旋转归一化。一般分为36个方向bin,每个梯度的权重是其幅度经过高斯加权的值,给相邻的两个bin投票。直方图还会经过平滑和插值。最终得到主方向 θ。
现在可以提取SIFT描述子了。首先将特征区域划分为16个小区域,每个区域统计8个方向bin的梯度直方图,得到128维的特征向量。这里划分小区域需要用到插值。划分的区域是方形的,但是LoG检测到的特征是圆形的,所以要用 θ 旋转原图,然后划分。
一张图可以提取到很多个128维特征,这些特征可以用来进行图像匹配、物体识别等任务。
Graph Cuts 图像分割#
也就是用“最大流最小割”进行图像的划分。把图像的每个像素看作一个节点,连接像素之间的边容量由像素值的相似度决定(可以是局部连接,可以是全连接)。通过求解最大流最小割问题,可以得到一个划分,将图像分为前景和背景。
在我看来难点在于如何构造 s 和 t。这个算法必须提供“前景/背景的先验概率”,每个节点都连接到 s 和 t,边容量和这个概率正相关。用户可以提供一些种子点,告诉算法哪些像素是前景/背景,此时这些种子点的容量(到s或t)会被设置为无穷大,实现强制分类。
举个简单的例子:先验认为前景是亮的,背景是暗的,那对每个像素,就用 灰度值 作为连接到s的容量,用 (灰度上限-灰度) 作为连接到t的容量。
Meanshift 图像分割#
输入:
- 样本:[样本数, 特征维度]
- 半径 R
- 收敛阈值 ϵ
算法:
- 取当前样本的第一个,计算其在半径 R 内的所有点的均值,得到一个新的点。
- 如果新点与旧点的距离小于 ϵ,则认为收敛,并将范围内的点归为一类,从总样本中移除;否则,将新点作为当前点,重复步骤1。
主动轮廓算法#
目标:先人为给出一个初始轮廓,算法通过迭代优化,使轮廓逐渐收敛到目标边界。
SNAKE算法#
人给出的轮廓是一堆点(从点得到轮廓可以用样条插值等方法)。基本原理是演化使得能量最小。引用知乎文章的图:
Esnake=∫01Eint(v(s))+Eext(v(s))ds
这是连续的表述;对于离散情况,s 看成轮廓上某个点归一化编号(虽然相邻点实际距离不一样,但是 Δs 是常数),v(s) 就是具体某一个控制点的坐标(位置向量)。因此离散公式如下:
Esnake=i=1∑NEint(vi)+Eext(vi)
Eint 是内部力,Eext 是外部力。外部力很好解释:图像梯度。 Eext(v(s))=−∥∇I(v(s))∥2,最小化总能量需要最大化图像梯度的幅值,也就是让轮廓尽可能靠近边界。
内部力分为两个部分:弹性力和弯曲力 Eint=αEelastic+βEbending。弹性力是为了让轮廓尽可能短,弯曲力是为了让轮廓尽可能平滑。
- 弹性力的定义如下:
Eelastic(v(s))=dsdv2
切向求导,代表曲线长度变化率。最小化这个值要求曲线长度尽可能小、且曲线均匀拉伸。
- 弯曲力的定义如下:
Ebending(v(s))=ds2d2v2
二阶导含义为曲率,最小化这个值要求曲线尽可能平滑。
Level Set 水平集方法#
SNAKE 模型的轮廓不好合并/分裂,无法处理多个物体、孔洞等。水平集方法的核心思想是将轮廓表示为三维曲面在二维平面上的一个等高线。通过演化这个曲面,使得等高线逐渐收敛到目标边界。水平集方法可以自然地处理轮廓的合并和分裂,适用于复杂的图像分割任务。
图像的变换#
先说最本质的。变换用齐次坐标,使得平移也可以用矩阵乘法表示。
找原图四个定点,拉伸到目标位置,求这个拉伸的变换。已知的是输入和输出的四个对应顶角,记一组对应的顶点为u(原图中)和v(纠正后)。为了编程实现考虑,此处是行向量。
[v1v2v3]=[u1]a11a21a31a12a22a32a13a23a33(1.1)
最终坐标齐次化:
v=[v1/v3v2/v3](1.2)
有4组点,一组点有两个方程,可以解8个未知数,但矩阵有9个未知数。由于进行了归一化,所以幅度无关(指变换矩阵A可以缩放),因此可以消去一个变量,比如就让a33=1。于是有以下方程:
v1v2=u1a13+u2a23+1u1a11+u2a21+a31=u1a13+u2a23+1u1a12+u2a22+a32
整理得
[a11a21a31a12a22a32a13a23]u1u21000−u1v1−u2v1000u1u21−u1v2−u2v2=[v1v2]
其他4组点的系数矩阵拼起来,求逆就可以求解了。
变换作用到图片#
公式(1.1)描述了从原图像到目标图像的变换方法,这对于连续场景来说很方便(比如webgl),但是现在目标图像也是离散的,因此最合适的做法是查询目标图像的像素在原图像中对应像素的位置,如果位置不是整数,则使用双线性插值。
这意味着上述求解的变换矩阵A要求逆。其实可以避免,只要交换u和v就行。实际应用时,也不必对每个像素的坐标乘A进行变换,根据线性性质,只要求出(1,0,0)、(0,1,0)、(0,0,1)的对应坐标e、f、g,对目标图像坐标为(i,j)的点,按照(i⋅e+j⋅f+g)线性组合,再归一化即可,而e和f的整数倍也是可以预先算好的。
假设已经从目标图像t中位置(i,j)得到了原图像o中对应像素的坐标,下面进行双线性插值。记小数和整数部分分别为(x,y)和(X,Y),则
t[i,j]=(1−x)(1−y)⋅+x(1−y)⋅+(1−x)y⋅+xy⋅o[X,Y]o[X+1,Y]o[X,Y+1]o[X+1,Y+1]
rigid: 刚性变换,只包括旋转和平移
scale: 缩放变换,可以改变比例,会保持平行关系
shear: 剪切变换,也保持平行关系
放射变换指的是保持直线和平行的变换。具体来说变换公式为(还是列向量好看):
v1v21=a11a210a12a220a13a231u1u21
列代表变换后的基底。可见只有6个自由度。
考题:仿射变换能否将长方形变为正方形?——能
投影(透视)变换#
如一开始推导的,有8个自由度。
考题:透视投影能否将矩形变为圆形?——不能
信息论 (没考)#
- 熵: H(X)=−∑ip(xi)logp(xi)
- 联合熵: H(X,Y)=−∑i,jp(xi,yj)logp(xi,yj)
- 条件熵: H(X∣Y)=−∑i,jp(xi,yj)logp(xi∣yj)=H(X,Y)−H(Y)
- 互信息: I(X;Y)=∑i,jp(xi,yj)logp(xi)p(yj)p(xi,yj)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
- 交叉熵: H(p,q)=−∑ip(xi)logq(xi) 输入是两个分布;联合熵输入是两个随机变量
- KL散度: DKL(p∥q)=∑ip(xi)logq(xi)p(xi)=H(p,q)−H(p)